Multi-Modal Manipulation via Multi-Modal Policy Consensus
- 로봇은 다음과 같은 다양한 modality(RGB images, Point clouds, Tactile signals, Learned visual features)를 사용함. modality는 서로 보완적일 수 있고 (예: vision vs. touch), 중복될 수도 있음 (예: RGB-D vs. point cloud). 이를 효과적으로 통합하는 것은 여전히 어려운 문제
- 기존 방법들은 각 modality의 feature를 하나의 큰 벡터로 이어붙이는 방식을 사용함. 하지만 다음과 같은 한계를 가짐
- modality 간 기여도를 균형 있게 조절하는 원리가 없음
- 새로운 modality가 추가되거나 일부 modality가 사라질 경우 유연하게 대응하지 못함
- 결과적으로 suboptimal performance 발생 가능
- 또한 기존의 monolithic architecture는 새로운 센서가 추가될 경우나 기존 센서가 고장/누락될 경우 전체 모델을 다시 학습해야 함
- 따라서, 각 modality를 강제로 fusion하는 대신 각각을 distinct contributor로 취급하는 구조적 대안이 필요하다고 주장
- 논문에서는 compositional generative models에서 영감을 받아서, 로봇 policy를 하나의 monolithic policy 가 아닌 modality-specific experts로 factorization
- 여러 expert의 출력을 하나의 unified policy로 결합하기 위해 router network를 사용함. router는 학습 과정에서 consensus weights를 학습. 이 weight를 통해 각 expert의 기여도를 조절
Contribution
- monolithic feature concatenation의 대안으로 modality-specific expert + learned consensus weights 구조 제안
- RLBench multi-task simulation benchmark에서 성능 검증. physical perturbation, runtime disturbance, sensor corruption에 대한 robustness 검증
- perturbation-based importance analysis 수행. task context 변화에 따라 modality 의존성이 어떻게 이동하는지 정량적으로 분석
Approach

Problem Formulation
- dataset of expert demonstration
- : action at timestep t
- : N sensory modalities
- 안의 각자다른 정보를 이용해서 를 학습하는것이 목표
- 각 modality 는 modality specific encoder를 통해서 latent embedding 인코딩됨. embedding 은 modality 정보 + robot state 정보 (joint angle, gripper status 등)를 포함함
- (ground-truth action), (action 후보), (diffusion timestep k에서 noise가 추가된 action)
- 각 modality i 에 대해서 개의 sub policy (parameter ) 를 학습. 각 sub policy에 대해서 energy function 와 diffusion score 을 정의
- modality index: i → 개의 sub policy 존재
- 각 sub-policy는
- 각 sub-policy는 파라미터 를 가짐
- 논문에서는 로 설정해서 complementary behavioral mode를 capture했다고 함
- router network 는 embedding 를 consensus weight 에 매핑. softmax로 정규화됨
Energy-Based Policy Composition
- policy는 energy fuction으로 봄. 낮은 energy는 선호되는 action, 높은 energy는 비선호 action. base policy 는 다음과 같음.
- 이러한 policy들을 조합하는 것은 확률 분포를 곱하는 것과 동일. 에너지 관점에서는 에너지 합과 동일

- router weight 가 현재의 state에 따라서 각 modality의 영향을 결정함.
- feature concatenation은 모든 modality를 shared network에 통과 → 통계적으로 드문 signal은 suppression 가능
- 논문에서 제안한 방식은 modality별 energy를 분리 유지. sparse하지만 중요한 신호가 유지됨 → energy function을 개별적으로 보존
Compositional Policy Factorization
- policy를 두 단계로 factorize해서 inter/intra-modality structure를 포착하고자함

- 는 composite policy for modality i, 는 complementary sub-policies(modality i 내부의 sub-policy, 서로 보완적인 behavioral mode를 담당). 는 router가 결정하는 weight
- 각 modality-specific policy는 최종 action에 대해 특정 behavioral constraint를 부과함
- 기존 Feature Concatenation은 모든 modality를 하나의 네트워크에 통과 sparse signal이 suppression될 수 있음
- 논문의 제안 방식은 는 독립적으로 학습됨.,tactile처럼 드물지만 중요한 modality도 유지됨. 최종 영향력은 router weight 를 통해 조절됨
Score-Based Implementation via Diffusion Models
- 각 base policy 는 Denoising Diffusion Probabilistic Model (DDPM) 로 구현됨
- Diffusion 모델은 score-matching energy-based model로 해석 가능. distribution 곱은 score 합으로 구현 가능
- Intra-Modality Composition: 한 modality 내부 sub-policy들의 score 평균

- Inter-Modality Composition: Router weight를 이용한 최종 score 계산
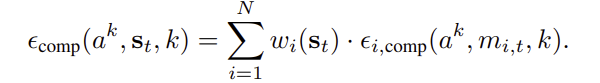
- 각 modality score는 gradient field 역할. router가 weight를 부여해 이 gradient들을 결합. energy-based composition과 diffusion score composition을 연결
Router Network
- Router R_ψ는 modality-specific embeddings 를 consensus weights 로 매핑
- weight들은 softmax로 정규화. . modality의 상대적 영향력 의미
- weight들이 역할. 각 expert의 action proposal을 조정
- training 동안 학습됨, 실행 시 고정됨
Advantages Over Existing Fusion
- 논문에서 제시하는 장점은 다음과 같음
- Robustness to Sparsity: tactile처럼 드문 modality도 suppression되지 않음
- Modularity: expert 독립적 학습 가능, 새로운 modality 추가 시 전체 재학습 불필요
- Interpretability: 가 modality 영향력 직접 표현
- Principled Consensus: energy-based composition 원리에 기반, 단순 feature fusion이 아님
Experiment


- 논문은 다음 세 가지 연구 질문을 검증하기 위해 실험을 수행
- Modality sparsity가 존재하는 작업에서 compositional architecture가 feature-level fusion보다 성능이 좋은가?
- 모델이 context-dependent modality reliance를 학습하는가? 또한 새로운 expert를 재학습 없이 추가할 수 있는가?
- 정책이 physical perturbation, sensor corruption 상황에서도 robustness를 유지하는가?
Experimental Setup
- Simulation
- Benchmark: RLBench
- 사용한 4개 task: open box, open drawer, take umbrella out of stand, toilet seat up
- Train: 200 demonstration episodes
- 평가: 200 unseen configurations
- Real-World
- 로봇: UR5e manipulator
- 장비: dual cameras, tactile sensors
- 수행 task: occluded marker picking, spoon reorientation puzzle insertion
- 수집한 teleoperation demonstration 수
- marker picking: 80
- spoon reorientation: 60
- puzzle insertion: 50
Sensory Modalities
- Simulation
- 사용 modality:
RGB images (2 cameras)
Point Cloud (PCD)
3D semantic features (pretrained DINO model로 추출)
- 사용 modality:
- Real-World
- RGB: Intel RealSense D415 2대, 해상도: 96 × 128
- Tactile: FlexiTac sensors
- 각 finger에 tactile pad 장착, 12 × 32 sensing units, 각 unit 공간 해상도: 2mm
Baselines
- Simulation Baselines
- Single-modality policies:
RGB-only
PCD-only
DINO-only
- Feature concatenation baseline
모든 modality embedding을 결합
- Factorized MoE fusion
soft routing 기반 mixture-of-experts
- Single-modality policies:
- Real-World Baselines
- RGB-only policy
- RGB + Tactile feature concatenation
Metrics
- Primary metric: Success rate
- Secondary metric: Completion time (성공한 trial에 한해 측정)
Main Results
- Simulation Performance
- 제안 방법의 평균 성공률: 66%
- Feature concatenation baseline: 56%
- 상대적 개선: 18%
- 파라미터 증가량: +0.7M (전체 대비 0.3% 증가). 매우 작은 파라미터 증가로 성능 향상을 달성했다고 보고
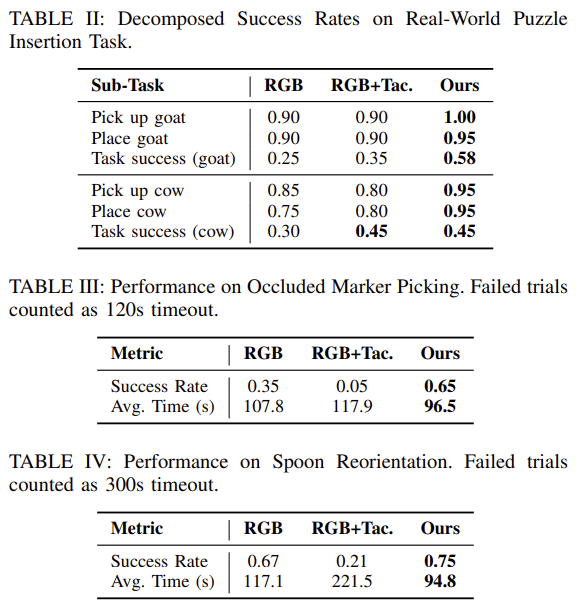
- Real-World Performance
- 각 real-world task에서 가장 높은 성공률을 기록:
Occluded Picking: 65%
Spoon Reorientation: 75%
Puzzle Insertion: 52%
- 성공한 trial 기준 평균 completion time도 가장 낮음
- 각 real-world task에서 가장 높은 성공률을 기록: