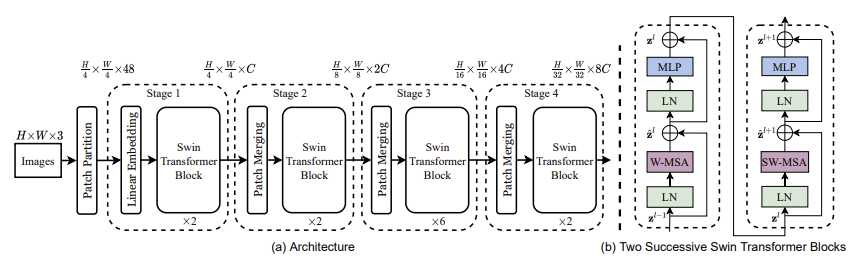
NT 컴퓨터비전 스터디에서 이번주에는 Grounded Language-Image Pre-training(GLIP) 논문을 정리하기로 했다. **틀린내용 다수 존재합니다. Abstract - 본 논문은 grounded language-image pre-training(GLIP)을 제안 - GLIP은 object detection과 pretraining을 위한 phrase grounding을 통합, 이것은 두가지 장점이 있음 1) GLIP이 object detection과 grounding data로 부터 두 task를 모두 개선하도록 학습을 함 2) GLIP은 grounding box를 만들면서 image-text 쌍을 만들수있음 - GLIP은 2천7백만개의 이미지-텍스트 쌍 데이터로 학습 - 다양한 객체..