NT 컴퓨터비전 스터디에서 이번주에는
Grounded Language-Image Pre-training(GLIP) 논문을 정리하기로 했다.
**틀린내용 다수 존재합니다.
Abstract
- 본 논문은 grounded language-image pre-training(GLIP)을 제안
- GLIP은 object detection과 pretraining을 위한 phrase grounding을 통합, 이것은 두가지 장점이 있음
1) GLIP이 object detection과 grounding data로 부터 두 task를 모두 개선하도록 학습을 함
2) GLIP은 grounding box를 만들면서 image-text 쌍을 만들수있음
- GLIP은 2천7백만개의 이미지-텍스트 쌍 데이터로 학습
- 다양한 객체에 대한 인식 task에서 강력한 zero-shot, few-shot 전이가능성을 보여줌
Introduction
- 비전 모델은 보통 미리정해진 객체 카테고리안의 객체를 예측하도록 학습되는데, 이것은 실생활에서 적용되기 어려움
- 기존 CLIP은 image-level의 visual representation이 이미지-텍스트 쌍으로 잘 학습되는것을 보임
- 다만 세밀한 이미지에 대한 이해를 필요로하는 object detection, segmentation 등.. 은 object-level visual representation이 요구됨
- 본 논문에서는, phrase grounding(문장과 이미지안의 객체의 상호관계를 인지하는것)이 객체수준의, 언어를 이해하는, 맥락을 잘 이해하는 visual representation을 잘 학습하는 것을 보여줌
Unifying detection and grounding by reformulating object detection as phrase grounding
- objection detection 모델이 이미지만 받는것이 아니라 모든 인식되야하는 후보 객체를 포함하는 텍스트도 input으로 받음
- box classifier 내부의 object classification logits을 word-region alignment score로 바꾸면서, 어떤 object detection 모델도 grounding model이 될수 있음
- CLIP과 다르게 GLIP에 적용된 deep cross-modality fusion은 언어를 이해하는 고수준의 visual representation을 학습할 수 있게 해주고, 더 좋은 transfer learning 성능을 달성하게 해줌
Scaling up visual concepts with massive image-text data
- 좋은 grounding 모델(선생님 모델)이 있다면, 그것을 활용하여 자동적으로 image-text 쌍에 해당하는 bounding box를 만들어 낼 수 있음
- GLIP-Large 모델(학생 모델)을 2천7백만개(2천4백만개는 크롤링, 3백만개는 사람이 라벨링)한 이미지-텍스트쌍으로 학습 가능했음
- 2천4백만개의 이미지-텍스트쌍에는 confidence score가 0.5가 넘는 78백만개의 bounding box가 존재(선생님 모델로 만들어진)
- 이렇게 좋은 선생님 모델이 만든 sementic rich 데이터는 sementic rich한 학생모델을 만들수 있음
Transfer learning with GLIP: one model for all
- grounding reformulation과 semantic-rich pre-training은 domain transfer를 용이하게 해줌
- GLIP은 추가적인 인간의 annotation없 다양한 task로 transfer될 수 있음
- 13개의 object detection모델에 평가를 진행했고, zero-shot에서도 좋은 성능 보임
Grounded Language Image Pre-training
- object detection과 phrase grounding은 물체를 localize하고 align한다는 점에서 유사성이 존재
- 전통적인 object detection task를 grounding problem으로 만듬 (reformulation)
- 이미지와 텍스트간의 deep fusion을 제시
Unified Formulation
- 기존 object detection 모델은 cnn이나 Transformer같은 backbone으로 box와 지역 feature를 얻고 box classifier와 box regressor로 classification loss와 localization loss로 학습

Object detection as phrase grounding
- 각각의 region이나 box를 c개의 class로 분류하는 것이 아니라, 각 지역을 text prompt의 c phrase로 align함
* 예를 들어, [person, bicycle, car, ...., toothbrush]같은 class들이 있을때, 가장 간단한 방법은 다음과 같이 prompt를 만드는것이다. Prompt="Detect: person, bicycle, car, ..., toothbrush"
- 사용하는 언어 모델에 따라서 prompt를 다르게 디자인할 수 있는데, BERT같은 경우에는 사람에게 익숙한 prompt보다, “person. bicycle. car. ... . toothbrush”와 같은 prompt가 더 좋은 성능을 보임
- grounding 모델에서 image region과 단어의 alignment score를 다음과 같이 계산
* P는 language encoder에서 얻어진 word/token feature, P는 식2)의 W와 같은 역할, region-word aligment인 Sground는 Scls를 대체
Equivalence between detection and grounding
- 위와 같은 reformulation으로, 어떤 detection 모델도 grounding 모델로 바꿀수 있음
- 그리고 detection모델과 grounding 모델은 이론적으로 training과 inference에서 동일함
* 예를들어 DyHead모델은 reformulation 전후로 COCO val2017데이터셋에서 동일한 성능을 보임
- reformulation을 하면서 pre-trained phrase grounding model은 바로 사용될 수 있었고, 이것은 GLIP모델이 zero-shot으로 어떤 detection task에서 작동할 수 있는것을 보여줌
Language-Aware Deep Fusion
- 식3)에서 볼 수 있듯 이미지와 텍스트는 각각의 인코더에서 인코딩되고 alignment score를 계산할 때 fuse되는데 이것을 late-fusion 모델이라고 함
- 논문에서는 이미지와 텍스트 정보를 인코딩 layer의 마지막 몇 단계에서 fusion하는 deep fusion을 제시함
*) 예를들어 DyHead를 이미지 인코더로 BERT를 텍스트 인코더로 사용할때 deep fused 인코더는 다음과 같음
- L은 DyHead에서의 DyHeadModule의 개수, BERTLayer는 사전학습된 BERT위에 추가된 BERT layer
- O0은 vision backbone에서의 visual feature, P0은 BERT에서의 token feature
- cross-modality communication은 cross-modality multi-head attention module( X-MHA )으로 진행 -(4)
- (5)와 (6)식에서 single modality fusion과 업데이트 진행됨
- Deep fusion 인코더는 두가지 장점이 있었음
1) phrase grounding performance를 개선함
2) learned visual features language-aware를 만들어서 모델의 예측이 text prompt에 기반하도록 함
Pre-training with Scalable Semantic-Rich Data
- 사람이 직접 annotation하는것은 비용이 많이듬
- self-training 방법으로 데이터를 늘리려고 했음
* 사전 학습된 detector인 teacher모델이 raw image에서 box를 예측하고 pseudo detection label을 생성하여 student model을 학습
- 그러나 teacher 모델은 concept pool내의 데이터에 국한될 수 밖에 없음
- GLIP모델은 detection 데이터셋과 grounding 데이터셋 둘다로 학습을 할 수 있음
- 논문에서는 grounding 데이터가 풍부한 semantic을 제공해서 localization이 용이하고, self-training으로 데이터가 늘어날 수 있다고 말함
- detection 데이터를 scaling up하는 대신에, grounding 데이터를 scaling up함
- GLIP을 사람이 직접 annotation한 detection 데이터셋과 grounding 데이터셋으로 사전학습함
- 웹에서 수집된 이미지 텍스트쌍에 대한 bounding box를 찾기위해서 선생 모델을 사용
- 학생모델은 사람이 직접 라벨링한 데이터와 자동 생성된 데이터를 모두 통해서 학습
- 학생모델이 선생모델을 능가할 수 있는 이유는, 선생모델은 언어맥락과 언어 일반화를 사용하여 원래 알지 못하는 개념을 ground
Transfer to Established Benchmarks
- 사전학습 이후에, GLIP은 grounding과 detection 모두에 적용될 수 있음
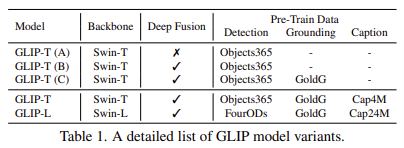
- 논문에서는 5개의 변형 GLIP을 학습하여 3가지 핵심 테크닉을 확인함
1) unified grounding loss
2) language-aware deep fusion
3) detection과 grounding데이터에 대한 사전학습
- GLIP-T (A)
- DyHead에 기반, classification loss를 word-region alignment loss로 대체, Swin-T backbone, O365로 사전학습
- GLIP-T (B)
- language-aware deep fusion 사용, O365만으로 사전학습
- GLIP-T (C)
- O365와 GoldG(사람이 labeling한 데이터) 등으로 사전학습
- 사람이 labeling한 데이터에 대한 효과를 검증하기 위해서 만들어짐
- GLIP-T
- Swin-Tiny backbone
- O365, GoldG, Cap4M(image-text쌍은 웹에서, bounding box는 GLIP-T로 생성)으로 사전학습
- GLIP-L
- Swin-Large backbone
- FourODs, O365, OpenImages, Visual Genome, ImageNetBoxes 으로 학습 (COCO 제외)
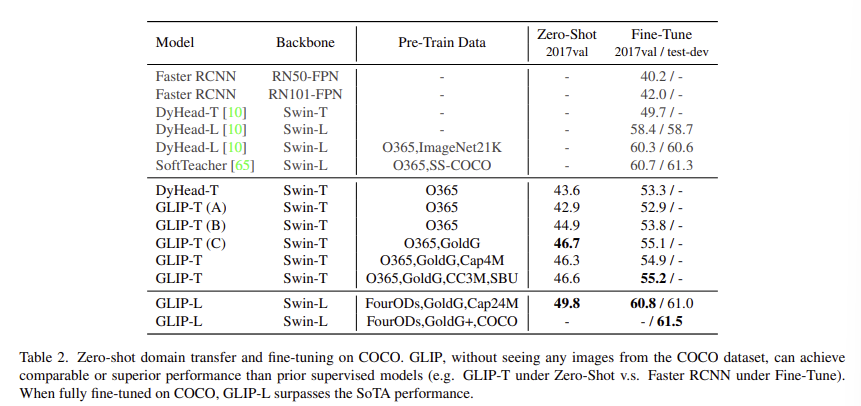
Zero-Shot and Supervised Transfer on COCO
- 논문에서는 zero-shot domain transfer, supervised transfer 두가지 세팅에서 평가를 진행
- fine-tuning 진행시 GLIP-L모델(사전학습시 COCO데이터셋을 포함)의 성능을 측정해봄