TNT 컴퓨터비전 스터디에서 이번주에는 Swin Transformer 논문을 정리하기로 했다.
논문: https://arxiv.org/pdf/2103.14030.pdf
Abstract
- 논문에서는 새로운 vision분야에 접목된 Transformer로써 Swin Transformer를 제시
- 기존에 자연어분야에서 쓰이던 Transformer가 컴퓨터 비전분야에 접목되는데에는 이미지 내에서의 큰 패턴변화나 텍스트에 비교했을때 많은량의 픽셀수 같은 어려움이 존재
- 논문에서 Shifted window를 통해 연산이 진행되는 계층적(hierarchical) Transformer를 제안
- Swin Transformer가 사용하는 계층적 구조는 self-attention 연산을 하면서 효율성과 다양한 이미지 크기에 적용되는 유연성이 있음
- Swin Transformer는 clasffication, object detection, semantic segmentation 등에서 SOTA 모델을 능가하는 좋은 성능을 보임
Introduction
- 컴퓨터 비전분야에서 CNN이 강력한 모습을, 자연어분야에서는 attention과 Transformer가 강력한 모습을 보여왔음
- CNN처럼 Transformer를 컴퓨터 비전분야에서 general purpose backbone 수준으로 활용하고자함
- 자연어 분야에 쓰이던 Transformer를 컴퓨터비전 분야에 활용하는데 두가지 큰 어려움이 존재
1. 이미지 같은 visual element는 work token과 다르게 크기가 다양함
2. 문단안의 단어의 개수에 비해서 이미지상의 pixel수는 정말 많은(high resolution)데 그렇게 되면 Transformer의 계산복잡도가 높아짐
- 위와같은 문제를 해결하기위해 범용적이고 n의 계산복잡도를 가지는 Swin Transformer라는 Transformer backbone모델을 제시
- Swin Transformer는 아래 사진과 같이 계층적 feature map을 만드는데, 이렇게 되면 FPN, U-net같은 dense prediction이 가능해짐


- 위의 사진처럼 겹치지 않는 window로 이미지를 분할하고, 분할된 픽셀(빨간선으로 나눠짐)들로 self-attention진행
- 이러한 방법으로 계산복잡도가 선형적으로 되고, Swin Transformer가 다양한 컴퓨터비전 task에 범용적인 backbone으로 사용될 수 있게됨
- Swin Transformer는 window partition이 이동(shift)하는것이 주요한 특징인데, 위의 사진과 같이 l번째 layer에서 경계선으로 나뉘어있던 부분이, 다음 l+1번째 layer에서는 window partition이 이동하게 되어 같은 window에 포함되어 연산되면서 연결되는 효과가 있음
- Image classification, object detection and semantic segmentation에서 좋은 성능을 보임
Method
Overall Architecture
Swin Transformer의 전체적인 구조는 아래의 사진과 같다.
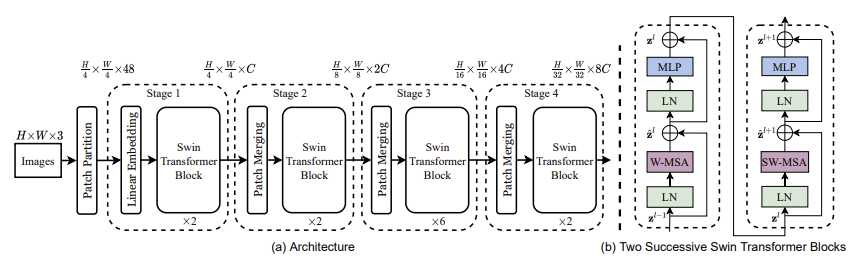
- 논문에서는 patch 크기를 4x4로 설정, 3차원 RGB이미지를 입력으로 받았을때 각 patch의 feature dimension은 4x4x3(=48)
- token(Transformer에 들어갈 단위)의 개수는 H/4 x W/4
Stage1
- 각 patch의 raw-valued feature에 해당하는 48차원의 벡터를 Linear Embedding을 통해 C차원으로 project (token 개수는 유지되어서 H/4 x W/4 개)
- 약간 변형된 self-attention을 가진 Swin-Transformer block에 patch token들이 입력됨
- Stage1을 거친 feature map의 크기는 H/4 x W/4 x C가 됨
Stage2
- 계층적(hierarchical) representation을 만들기 위해서, patch들끼리 병합하는 과정이 필요함
- patch들끼리 병합하는 과정을 Patch Merging layer에서 수행
- Stage1에서 1x1 patch들을 붙여서 2x2 patch로 만듬, 그렇게 되면 patch(token)의 개수는 H/8 x W/8개가 되고, 각 patch의 dimension은 4(2x2)C가 됨
- 4C dimension을 downsampling해서 2C dimension으로 만들어줌
- H/8 x W/8개의 2C차원을 가진 feature들이 각각 Swin-Transformer block을 거침
- 최종적으로 Stage2를 거친 feature map의 크기는 H/8 x W/8 x 2C가 됨
Stage3,4
- Stage2와 동일한 과정을 거쳐서 Stage3이후에는 H/16 x W/16개의 4C차원의 벡터가, H/32 x W/32개의 8C차원의 벡터가 출력
- 이렇게 각각의 Stage에서 계층적인(hierarchical) representation을 만들어 냄으로써, 기존의 CNN모델에서와 같이 feature map을 만들어 낼수 있음. 따라서 Swin Transformer가 CNN을 대체하는 backbone이 될수 있음
Swin Transformer block
- Swin Transformer는 기존의 Transformer block에서 multi-head self attention(MSA) 모듈을 shifted window를 기반으로한 module로 변경하면서 만들어짐


- 위의 그림에서 볼수 있듯 Swin Transformer Block은 shifted window을 기반으로한 MSA module(W-MSA)이 존재함
- shifted window을 기반으로한 MSA module이후 2층의 MLP와 GELU를 지나고, W-MSA이전에 LayerNorm(LN)계층을 지남
Shifted Window based Self-Attention
- 기존 Transformer구조는 global self-attention연상을 하는데, 이것은 계산복잡도에서 quadratic complexity(n^2)를 보여줌
- 따라서 기존 Transformer는 해상도가 높아졌을때 연산량이 너무 많아져서, 다양한 컴퓨터비전 task에 적용하기가 힘듬
- 논문에서는 local-window에서의 self-attention연산으로 위의 문제를 해결하고자함.
- hxw크기의 이미지에서 한 window가 M x M patch를 가진다면, global self-attention에서의 계산복잡도와 local-window에서의 self-attention연산의 계산복잡도는 다음과 같음

- (1)의 기존 attention연산은 quadratic complexity를, (2) local window에서 attetion연산은 linear complexity를 보임
- 위 사진을 다시 참고한다면, Swin Transformer Blocks의 첫번째 모듈은 regular window partitioning strategy(W-MSA)를 사용
- regular window partitioning strategy는 top-left 픽셀에서 시작해서 window들이 균일하게 분할됨
- Swin Transformer Blocks의 두번째 모듈은 이전 첫번째 모듈의 window위치에서 (M/2, M/2)만큼 이동한 변형된 window configuration을 이용(SW-MSA)
- 두 모듈의 연산은 다음 수식과 같음

Architecture Variants
- base 모델인 Swin-B와 더불어, Swin-B와 비교했을때 모델크기가 0.25배인 Swin-T, 0.5배인 Swin-S, 2배인 Swin-L을 구축
- Window size M=7, 각 head의 query dimension d = 32 그리고 각 모델의 hyper parameter는 다음과 같음(C=Stage1에서 channel number of the hidden layers)

Experiments

- Swin-B와 Swin-L는 기존의 SOTA 트랜스포머 기반 아키텍처와 주요 CNN 모델과 비교할 때, 뛰어난 속도-정확도 트레이드오프를 제공
- 또한 ImageNet-22K 데이터로 사전 훈련한 후 ImageNet-1K 데이터로 fine-tuning을 한 결과, 다른 모델들과 비교하여 우수한 성능을 보여주고 있음