*사이토 고키의 밑바닥부터 시작하는 딥러닝2를 공부하고 정리하는 내용입니다. 정리하는 과정에서 혹여나 잘못된 내용이 들어가 있을수 있습니다.
RNN은 BPTT에서 기울기 소실 또는 기울기 폭발이 일어나기 때문에, 시계열 데이터의 장기 의존 관계를 학습하기 어렵습니다. 이러한 문제를 해결하기 위해서 등장한 것이 RNN에 게이트를 추가한 LSTM과 GRU입니다. 책에서는 chap6에서 LSTM에 대해서 소개하고 있습니다.
LSTM
LSTM에는 RNN과 다르게 c라는 경로가 있습니다. 이것을 기억 셀(memory cell)이라고 합니다. 은닉상태에 해당하는 ht는 기억셀 ct에 tanh를 적용한 값입니다.

output 게이트
tanh(ct)의 값에 해당하는 ht의 출력을 담당하는 게이트를 output게이트라고 합니다. 이 output게이트에서는 tanh(ct)를 다음 LSTM셀로 얼마나 흘려보낼지 입력 xt와 ht-1로 부터 구합니다. 수식은 다음과 같습니다.
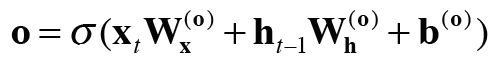
위와 같은 수식의 output게이트는 시그모이드 함수를 거쳐 도출되고, 이렇게 도출된 output게이트의 값은 tanh(ct)에 원소별 곱(아다마르 곱)을 하여 다음셀에 전달한 ht를 계산하게됩니다.


forget 게이트
LSTM셀에는 output게이트 뿐만 아니라, 이전 게이트로 부터 전달받은 ct-1로 부터 불필요한 기억을 잊게 해주는 forget게이트도 존재합니다.
forget 게이트 또한 output게이트와 동일하게 xt와 ht-1로부터 구하고 수식은 다음과 같습니다.

마찬가지로 이렇게 구해진 forget값을 ct-1와 원소별 곱(아다마르 곱)을 하여 다음 셀로 전달할 ct를 구합니다.

새로운 기억 셀
하지만 위에와 같이 잊기만 한다면 현재 입력에서의 새로운 정보를 반영하지 못합니다. 따라서 아래와 같이 xt와 ht-1로 부터 추가할 새로운 정보를 계산하고, ct에 더해줍니다.


input 게이트
마지막으로 위에서 진행했던 ct에 반영할 새로운 정보들을 계산한 g에 게이트를 추가합니다. 이것을 input게이트라고 하며, g의 각 원소가 새로 추가되는 정보로써의 가치가 얼마나 큰지 판단하는 역할을 합니다. 이전 게이트들과 마찬가지로 ht-1과 xt로 부터 연산하며, 수식은 다음과 같습니다.

이렇게 연산한 input게이트값을 새로추가할 정보를 나타내는 g에 원소곱으로 반영을 해준후에 ct에 반영하게 됩니다.

LSTM의 기울기 흐름
LSTM은 RNN의 기울기 소실/폭발을 해결하였다고 했는데 어떻게 해결할 수 있었을까요?
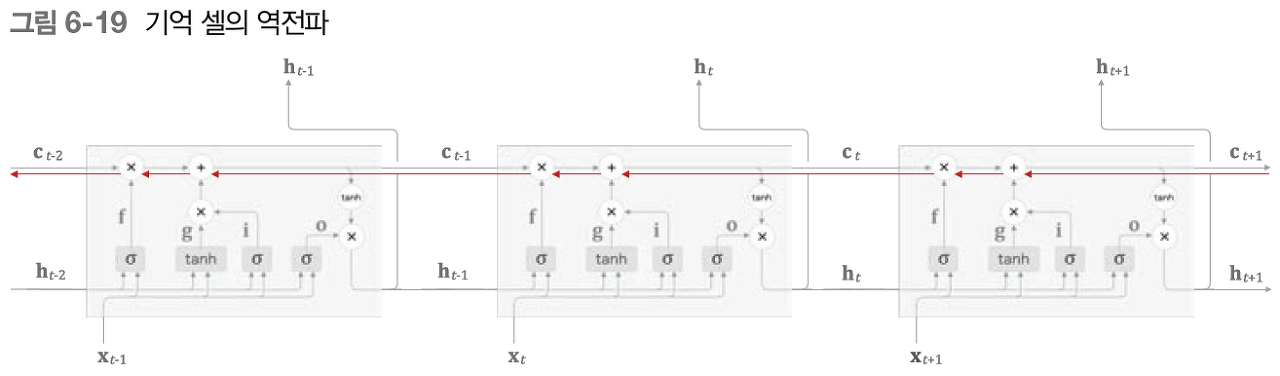
기억셀의 역전파의 흐름을 보게되면, 기억셀의 역전파에서는 +와 x만 지나게 됩니다. +를 지날때는 상류에서 전달된 기울기는 변하지않고, x노드에서 변하게 됩니다. 하지만 위에서 설명했듯, x는 행렬곱이 아닌 원소곱입니다. 매 시각 다른 게이트값을 이용하여 원소곱을 계산하기 때문에, 역전파시 곱셈의 효과가 누적되지 않아 기울기 소실이 일어나지 않습니다.
따라서 기억셀은 장기 의존 관계를 효과적으로 유지할 수 있습니다.
'DL' 카테고리의 다른 글
| [Paper Review] Learning Transferable Visual Models From Natural Language Supervision(CLIP) 논문 정리 (1) | 2023.09.03 |
|---|---|
| [NLP] 자연어처리 기초부터 Attention까지: seq2seq (0) | 2023.08.19 |
| [NLP] 자연어처리 기초부터 Attention까지: RNN (0) | 2023.08.18 |
| [NLP] 자연어처리 기초부터 Attention까지: word2vec(2) (0) | 2023.08.17 |
| [NLP] 자연어처리 기초부터 Attention까지: word2vec (0) | 2023.08.17 |