[Paper Review] Learning Open-vocabulary Semantic Segmentation Models From Natural Language Supervision 논문 정리
TNT 컴퓨터비전 스터디에서 이번주에는
Learning Open-vocabulary Semantic Segmentation ModelsFrom Natural Language Supervision 논문을 정리하기로 했다.
**틀린내용 다수 존재합니다.
**2023.11.06 기준 내용 추가/보강 예정..
Abstract
- 논문에서는 open-vocabulary semantic segmentation(OVS)의 문제에 대해서 고찰함
*OVS: 미리 정해진 카테고리 이외에 무작위 카테고리의 객체를 segmentation하는 task
1. 논문에서는 OVSegmentor라고 불리는 transformer에 기반한 OVS 모델을 제안
-> OVSegmentor는 웹에서 크롤링한 image-text 쌍을 사전학습하는데 사용됨
2. 논문에서는 masked entity completion과 cross-image mask consistency라는 두가지 학습을 위한 proxy task를 제안
-> masked entity completion: 텍스트로 전달된 캡션에서 모든 masked 객체를 찾는것을 목표로함. 이것은 모델이 이미지와 text사이의 fine-grained alignment를 학습할 수 있게해줌
-> cross-image mask consistency: 공통된 entity를 가진 이미지간의 지속적인 mask prediction을 학습할수 있게 해줌
3. CC12M에서 선별된 CC4M데이터셋을 구축
4. PASCAL VOC 2012, PASCAL Context, COCO Object 세개의 데이터셋에서 zero-shot transform을 진행함
논문에서 제안한 모델은 기존 SOTA모델이 사용한 데이터량의 3프로만 사용하고도 더 좋은 결과를 얻음
Introduction
- semantic segmentation에서 연구의 방향은 크게 2가지로 나뉨
1) pixel들을 다른 group으로 나누고, semantic label을 각 group으로 할당하는것
2) pixel단위의 classification으로 나누어서 각 픽셀을 한 class로 classification하는것
- 하지만 기존의 지도학습 방법의 semantic segmentation 접근법은 문제가 있음
-> 라벨링한는데 비용이 너무 큼
-> 정해진 라벨(카테고리)내에서만 segmentation을 할수 있어서, 새로운 데이터셋이 들어왔을때 또 다른 지도학습이 필요함
- 논문에서는 인터넷에서 image-caption 쌍을 수집하여 open-vocabulary sementic segmentation 모델을 학습하는것을 목표로함
- 하지만 문제점이 존재함
-> 대략적이고, 이미지 수준의 텍스트는 세밀하고, 픽셀단위를 학습해야하는데 어려움이 있음
-> 인터넷에서 수집된 데이터는 다양해서 모델이 시각적 불변성(visual invariance)을 약한 supervision으로 학습해야함
- 따라서 논문에서는 transformer에 기반한 OVS모델을 제안함
- 해당 모델은 zero-shot transfer를 통해서 임의의 class의 객체또한 segment 가능
- learnable group tokens을 도입하고, caption embedding과 group token을 정렬시키고, slot attention을 도입하여 이미지 패치를 그룹화함
- 논문에서 제시한 모델은 ground-truth masks나 추가적인 데이터셋으로 재학습이 필요하지 않기에 라벨링 비용과 transfer efficiency를 높힐 수 있었음
- 또 논문에서는 masked entity completion와 cross-image mask consistency 두가지 proxy task를 제안
-> masked entity completion: 모델이 모든 문장에서 주어진 masked 객체를 인지할수있게 해줌
-> cross-image mask consistency: 일관성있는 mask 예측을 하게 해줌
- OVSegmentor를 CC12M을 필터링한 데이터셋인 CC4M데이테셋으로 학습시키고, PASCAL VOC 2012, PASCAL Context, COCO에서 성능검증을 함
Architecture

Visual Encoder
- image-caption 쌍인 (I , T)가 주어지면 먼저 이미지를 P크기의 패치로 이미지를 나눔
- 나눠진 패치들을 이미지 토큰이 되어 MLP로 들어감- visual encoder는 transformer encoder와 binding module 두 부분으로 나뉨- image token들과 learnable group toke은 transformer encoder와 binding module에의해서 서로 붙어짐

- visual encoder는 위의 수식으로 나타낼수 있음
- 좌항의 G는 encoded group token들을, I는 output image token들을 나타냄
Transformer Encoder
- 위의 수식에서 transformer encoder에 해당하는 enc1과 enc2는 6개의 Transformer encoder layer(multi-head self-attention+layer normalization+FFN)로 구성됨
-> enc1: input으로 image patch+랜덤 초기화된 group token, output으로 중간단계의 인코딩된 group과 image tokens
-> enc2: binding module의 결과를 처리
Binding Module
- binding module은 slot-attention을 사용하여 image token을 group으로 모음(비슷하게 생긴 image patch는 같이 모이게됨)
- enc1에서 나온 결과를 input으로 받고, 그것을 linear transformations를 이용하여 query, key, value로 변환(아래그림참조)

- 기본적인 Transforer Decoder의 cross attention과 다르게, slot attention은 query간의 normalization을 수행
- 이것은 이미지 토큰이 하나의 group token이 되게 함
- binding module의 output은 밑의 그림과 같이 정의됨

* W^(bind)는 linear transformation
- 이것을 통해 각 픽셀과 group token의 correspondence를 얻을 수 있었음
Text Encoder
- text encoder에서는 세가지 변형(entire caption embedding, masked caption embedding, prompted entity embedding )으로의 인코딩을 진행
- 사전학습된 BERT를 사용
Constructing Entity Set
- nltk를 사용하여 자주 나온 entity(사람, 고양이, 셔츠 등..)만 유지하고, 추상명사들을 제외
- image-caption쌍에서, image-caption-entity 쌍 (I, T, E)을 얻을수있었음
Captioning Embedding
- (I, T, E) 쌍에서 caption에 해당하는 T는 BERT tokeniser로 토큰화됨
Masked Caption Embedding
- caption에서 entity를 모두 마스킹후(MASK 토큰으로 entity 대체) masked caption embedding을 수행
Prompted Entity Embedding
- (I, T, E) 쌍에 있는 entity를 포함하는 직접만든 prompt를 생성하고 그것을 임베딩
ex. "A painting of a { entity1 } and { entity2 } and { entity3 }"
Training
- group token들과 embedding token의 alignment를 세가지 proxy task(image-caption alignment, masked entity comple tion, cross-image mask consistency) 를 통해 학습하고자함.
Image-caption Alignment
- image-text 쌍에서 목표는 이미지-텍스트 임베딩을 align하는것
- visual embedding인 z^I는 group token의 평균, z^T는 caption embedding의 feature이고 둘다 256차원을 가지고 normalize됨
- image-caption contrastive loss는 다음과 같은 수식을 가짐

Masked Entity Completion
- masked entity completion의 목적은 모든 마스킹된 entity를 group token이 주어졌을때 찾아내는것
- Transformer Decoder에서 query를 masked caption embedding으로, group toke의 linear transformation은 key와 value로 설정
- contranstive loss는 다음과 같이 계산
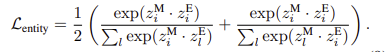
Cross-image Mask Consistency
- visual invariance를 강화하기 위해서 같은 entity를 가지는 이미지 사이에서 embedding을 계산하고 더 높은 유사성을 가지는 것을 채택

Training Objective
- 따라서 전체 loss function은 다음과 같음

* 이후 내용 추가예정