[DL 기초] 밑바닥부터 시작하는 딥러닝: 학습 관련 기술들(1)
인턴하는 회사에서 진행하는 세미나 7주차의 과제로 사이토 고키의 밑바닥부터 시작하는 딥러닝의 6 - 학습 관련 기술들 부분을 정리해 보고자합니다.
매개변수 갱신
신경망 학습의 목적, 즉 손실함수의 값을 최소화하는 매개변수값을 찾는것을 최적화(optimization)이라고 합니다. 심층 신경망에서는 매개변수의 수가 무수히 많고, 그 매개변수 공간에서 손실함수의 최소값을 만들어 내는 매개변수의 지점을 찾기란 굉장히 어렵습니다. 이전 단원에서는 매개변수에 대한 손실함수의 미분값을 도출해서 점점 최적의 값에 다가갔고, 이것을 확률적 경사 하강법(SGD)라고 소개한 바 있습니다.
책에서는 SGD를 먼저 소개하고, SGD 이외의 다른 최적화 기법을 소개하고 있습니다.
확률적 경사 하강법(SGD)

SGD는 위와같은 수식으로 나타낼 수 있습니다. W는 갱신할 가중치 매개변수를, dL/dW는 가중치 매개변수에 대한 손실함수의 기울기를, n(특수문자 넣을수 없어서 n으로 대체)는 학습률을 의미합니다. 이러한 수식을 가지는 SGD는 모델학습시에 매개변수를 갱신하는 optimizer으로써의 역할을 합니다.
SGD는 구현도 쉽고 간단하지만, 단점도 분명 존재합니다. 밑에와같은 수식을 가진 함수의 최솟값을 구한다고 생각해본다면, 다음과 같은 그래프를 먼저 그려볼수 있을것입니다.
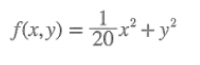

위의 그래프의 기울기를 시각화한다면 밑의 그림과 같을 것입니다.

이렇게 기울기는 대부분 최솟값이 되는 지점인 (x,y)=(0,0)을 가리키지 않습니다. 따라서 위의 함수를 최솟값을 만들어내기위해서는 다음과같은 비효율적인 움직임을 보이게 됩니다.

즉, SGD는 방향에 따라 기울기가 달라지는 비등방성 함수에서 경로 탐색이 비효율적입니다. 책에서는 이러한 SGD의 단점을 개선해주는 모멘텀, AdaGrad, Adam을 소개하고 있습니다.
모멘텀(Momentum)
모멘텀 기법은 수식으로 다음과 같이 나타낼수 있습니다.
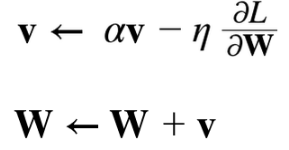
여기에서 새롭게 등장하는 v라는 변수는 속도에 해당합니다. 두식중에서 위의 식은 기울기 방향으로 힘을 받아 물체가 가속되는 물리법칙을 나타내고, 이 식에서 av는 물체가 아무런 힘을 받지 않을때 서서히 하강시키는 역할을 합니다.

그 결과로 다음과 같은 모멘텀에 의한 최적화 갱신경로가 나오게 됩니다. SGD와 비교했을때 지그재그 정도가 적은것을 확인할 수 있습니다.
AdaGrad
신경망 학습에서 학습률이 너무 작으면 학습시간이 너무 길어지고, 너무 크면 발산해서 학습이 제대로 이루어지지 않습니다. 이러한 학습률을 학습을 진행하면서 줄여가는 방법을 학습률 감소(learning rate decay)라고 합니다. 일반적으로 큰 학습률로 시작하여 학습률을 감소시키는데, 이렇게 매개변수 전체의 학습률을 일괄적으로 낮추는것에서 발전된것이 AdaGrad입니다.
AdaGrad는 개별 매개변수에 대한 학습률을 조정하면서 학습을 진행합니다.

위에서는 h라는 새로운 변수가 등장하는데, h는 기존의 매개변수에 대한 손실함수의 기울기 값을 제곱하여 더해줍니다. 이렇게 된다면 두식중 아래의 식에서 확인할 수 있듯 크게 갱신된 매개변수의 원소 일수록 학습률이 낮아집니다. 즉, 학습률의 감소가 매개변수의 각 원소마다 다르게 적용되는 것입니다.

이렇게 AdaGrad는 최솟값을 향한 효율적인 움직임을 보여줍니다.
Adam
앞에서 소개한 모멘텀과 AdaGrad를 합친기법이 Adam이라는 기법입니다. 책에서는 Adam에 대해서 간단히 설명을 진행하고 있는데, 모멘텀과 AdaGrad의 장점을 차용해서 매개변수 공간을 효율적으로 탐색한다고 합니다. Adam의 최적화 갱신경로는 다음과 같습니다.

가중치의 초깃값
신경망 학습에서 가중치 초기값을 어떻게 설정하느냐 또한 중요하다고 합니다.
책에서는 가중치 감소(weight decay)기법에 대해서 소개하고 있습니다. 이는 가중치 매개변수의 값이 작아지도록 학습을 진행해 오버피팅이 일어나지 않도록하는 기법이라고 합니다. 다만 가중치 매개변수가 작아지도록 학습시킨다고 해서 초기값을 0으로 설정하면 안된다고 설명하고 있습니다. 또한 가중치를 표준편차가 1인 정규본포로 초기화할 때 각 층의 활성화값 분포를 보이며, 시그모이드 함수에서는 기울기 소실이, 다른경우로 가중치를 표준편차가 0.01인 정규본포로 초기화할 때 다수의 뉴런이 비슷한 값을 출력하고 있음을 보이며, 표현력이 제한된다고 말합니다.
따라서 많은 딥러닝 프레임워크들에서는 이전 계층의 n개의 노드가 존재한다면 표준편차가 1/(n^(1/2))인 분포를 사용하여 가중치 매개변수를 초기화하는 Xavier 초기값을 사용합니다.
배치 정규화(Batch Normalization)
앞에서는 매개변수의 초기값에 대해서 알아봤는데, 각층의 활성화값 분포가 적당히 퍼지면 학습이 원활하게 수행됨을 알았습니다. 배치 정규화 기법은 각층에서 활성화를 적당히 퍼뜨리도록 강제하는 기법입니다.

배치정규화는 학습 시 미니배치를 단위로 데이터분포가 평균이 0, 분산이 1이 되도록 정규화합니다. 수식은 다음과 같습니다.
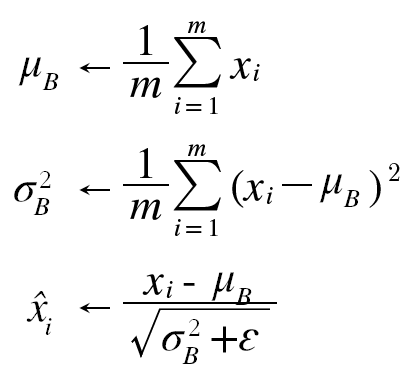
위의 수식에은 미니배치 입력 데이터 x1~xm의 기존 평균과 분산을 각각 0과 1로 바꿔줍니다. 이러한 연산을 활성화 함수 앞에서 진행하면서 데이터 분포가 덜 치우치게 만듭니다. 또한 이렇게 정규화된 데이터에 고유한 확대(scale)와 이동(shift) 변환을 수행합니다.

이러한 배치 정규화 알고리즘은 신경망의 순전파시에 적용됩니다. 배치 정규화 알고리즘은 학습속도를 개선해주고, 매개변수의 초기값에 크게 의존하지 않으며, 오버피팅을 억제해 주어 드롭아웃과 같은 기법을 진행하지 않아도 되게 해줍니다.