[Paper Review] Vision Transformer(ViT) 논문 정리
** 틀린 개념/구현 다수
이번 학기에 TNT학회 스터디로 논문리뷰 두번째로 ViT(Vision Transformer)를 하게 되었다.
ViT논문(https://arxiv.org/pdf/2010.11929.pdf)
Abstract
NLP 분야에서 transformer architecture는 기준이 되어온것과는 다르게, 컴퓨터 비전분야에서 transformer 구조의 적용은 제한적이여 왔습니다. 논문에서는 CNN 구조가 아닌 순수 transformer가 classification task에서 효과적임을 보일것이라고 합니다. ImageNet, CIFAR-100, VTAB 데이터셋에서 Vision Transformer(ViT)는 SOTA CNN과 비교했을때 더 좋은 결과를 얻었고, 학습시에 computational resource가 절감되었습니다.
1. Introduction
NLP분야에서는 Transformer의 computational efficiency와 scalability 덕분에 1000억개가 넘는 parameter를 가지는 거대한 모델도 학습시킬수 있었는데요, 컴퓨터 비전분야에서는 NLP에서 영감을 받아서 CNN구조와 self-attention구조를 결합한다거나 아에 convolution연산을 self-attention으로 대체하는것등 시도가 있었지만, attention의 어떤 목적성(?) 때문에 현대의 하드웨어 가속기에까지 확장되지 못했다고 합니다. 여전히 컴퓨터 비전분야에서(large-scale image recognition) ResNet이 state-of-art인것에 문제의식을 느낀듯 합니다.
논문에서는 이미지에 최소한의 수정을 거친 standard Transformer를 적용합니다. 그렇게 하기 위해서 마치 NLP에서 문장을 token(words)로 쪼개서 넣는것처럼, 이미지를 patch로 나누고 이 patch의 linear embedding의 sequence를 Transformer에 제공해서 지도학습의 방식으로 image classification을 하도록 학습시켰습니다.
ImageNet을 학습시켰을때, 이 모델은 비슷한 크기의 ResNet과 비교했을때 몇 퍼센트 정도 낮은 정확도를 보였습니다. 이렇게 조금은 실망스러운 결과를 보인이유는 Transformer가 CNN에 비해 inductive bias 부족해서 충분하지 못한 데이터를 학습했을때 generalization을 잘 수행하지 못했기 때문이라고 말합니다.
하지만 1400만개에서 3억개정도의 거대한 dataset을 학습했을때 ViT는 좋은 결과를 보였다고 합니다. ImageNet-21k, JFT-300M 데이터셋으로 pre-train되었을때, ViT는 SOTA 다중 이미지 인식모델과 비슷하거나 더 좋은 결과를 보였다고 합니다.
2. Related Work
3. Method
모델을 구성할때, 기존의 Transformer구조를 가능한 비슷하게 따르고자 하였고, 이러한 의도적인 간단한 구현법은 확장가능한 NLP Transformer architecture가 즉시 사용될수 있다는 이점을 가지고 있습니다.
3.1 Vision Transformer(ViT)

위의 그림에서 ViT의 전체적인 모습을 확인할 수 있습니다. 2D 이미지를 Transformer에 넣어주기 위해서
R^(H×W×C)의 차원에 속해있던 이미지를 R^(Nx(P^2xC))로 바꿔줍니다. 여기서 (H,W)는 원본 이미지의 해상도이고, C는 이미지의 채널수, (P,P)는 image patch의 해상도, N은 HW/P^2 즉 원본 이미지를 image patch로 나눠서 나오는 image patch의 개수입니다. 이렇게 N개의 (P,P)크기의 patch들은 trainable linear projection을 통해서 D차원으로 매핑되는데요, 이러한 projection의 output을 patch embeddings라고 부릅니다.
위치정보를 유지하기 위해서 position embeddings가 patch embedding에 추가됩니다. 논문에서는 2차원 position embedding을 사용했을때 성능 측면에서 개선이 없었기에 1차원 position embedding을 사용했다고 말합니다. 이렇게 생성된 position/patch embedding는 Transformer의 encoder의 input으로 들어가게 됩니다.
위의 그림의 오른쪽 부분에서 Transformer의 encoder가 어떻게 구성되어 있는지 확인할 수 있는데요, Transformer의 encoder는 Multi head self-attention과 MLP block이 번갈아가며 구성이 되는데 이러한 구성이전에 Layernorm을 거치게 된다고 합니다. 또한 그림에서 확인할 수 있듯이 residual connection이 존재합니다.
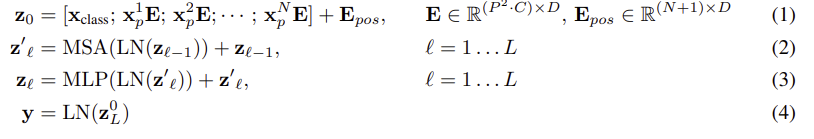
수식으로 나타낸다면 위의 그림과 같습니다. 식 (1)은 input에 대응하는 식입니다. Xclass는 classification token이고, Xp^NE는 각각 순서대로의 patch들입니다. Epos는 positional encoding 입니다.
식 (2),(3)은 Transformer encoder 내부의 식입니다. 식(2)는 Layer Normalize된 input이 Multi head attention 연산이후에 residual connection에 의해 z(l-1)과 더해지는 것이며, 식(3)은 Layer Normalize된 Multi head attention의 output값이 MLP로 연산된 이후에 residual connection에 의해 z'l과 더해지는 것입니다.
Inductive bias
위에서도 말했듯 ViT는 CNN에 비해서 image-specific iductive bias가 적습니다. CNN에서는 전체 모델 내내 2차원 neighborhood 구조와 translation equivariance가 숙성(?)됩니다. 그러나 ViT에서는 MLP만이 local하고 translationally equivariant하고 self-attention layer가 global합니다. 모델의 초기에 원본 이미지를 patch들로 나눌떄와 다른 해상도의 이미지의 position embedding을 조절할 때를 제외하고는 patch들의 2차원 위치와 공간적 정보에 대한 정보가 없고, patch들의 공간적 상관관계가 scratch부터 학습되어야합니다.
Hybrid Architecture
원본이미지를 잘라서 patch들을 만들어 내는것을 대안으로, CNN의 feature map으로 encoder의 input을 만들어 낼 수도 있습니다. 이러한 Hybrid 구조에서는 CNN feature map에서 나온 patch에 patch embedding이 적용될 수 있습니다.
3.2 Fine-Tuning and Higher Resolution
논문에서는 ViT를 대용량 데이터셋으로 학습시키고, 특정한 task를 위해서 fine tune하기 위해서 pre-trained prediction head를 제거하고 0으로 초기화된 DxK layer를 도입했다고 힙니다. K는 어떤 특정 task를 위한 class의 개수입니다. 그리고 이러한 방식은 고해상도에서 fine-tune하는데 성능향상이 있었다고 합니다.
즉, 모델의 입력으로 고해상도의 이미지가 들어왔을때, 나눠지는 patch크기가 똑같다면 sequence length가 길어질 것이고 그러면 ViT모델은 메모리 한계까지 sequence length를 다룰것이고 pre-train된 position embedding은 더이상의미가 없어질 것입니다. 따라서 논문에서는 pre-train된 position embedding에 대해서 원본이미지의 loaction을 참조해서 2차원 interpolation을 수행한다고 합니다.
4. Experiment
논문에서는 ResNet, ViT 그리고 이 둘의 hybrid 모델의 학습능력을 평가했습니다. 각 모델을 다양한 사이즈의 데이터로 학습시키고, 다양한 task에서 성능평가를 진행하였다고 합니다. pre-train을 진행할때 computational cost를 고려할 때, ViT가 state-of-art의 성능을 보여줬다고 합니다.
4.1 Setup
Datasets
모델을 학습시키기 위해서, ILSVRC-2012 ImageNet 데이터셋(1000개 클래스, 130만개 이미지), ImageNet-21k, JFT 데이터셋을 사용했고, 그리고 이런 데이터셋을 학습한 모델을 CIFAR-10/100, Oxford-IIIT Pets 등의 데이터셋에 transfer했다고 합니다.
Model Variants

위의 표에서의 ViT-Base와 ViT-Large는 BERT모델의 설정값에서 변수를 차용했고, ViT-Huge모델은 새로 추가했다고 합니다. 또한 baseline 모델로 ResNet을 사용했지만 Batch normalization layer을 제거했고 그 결과 transfer가 더 잘되었다고 합니다. ResNet과 ViT의 hybrid 모델에서는 한 픽셀크기로 patch를 만들었습니다.
Training & Fine-tuning
논문에서는 다음과같은 hyperparameter와 기법들로 ResNet을 포함한 모든 모델을 학습시켰습니다.
Adam
Batch size=4096
weight decay=0.1
Fine-tuning에서는
SGD with momentum
Batch size=512
fine-tuned at higher resolution: 512 for ViT-L/16 ( ViT-Large with 16x16 input patch size), 518 for ViT-H/14
4.2 Comparsion to state of art

ViT-L/16과 ViT-H/14을 SOTA CNN과 비교를 진행하였는데요, 지도 전이 학습을 진행한 ResNet과 ImageNet과 JFT-300M으로 반지도 학습을 한 EfficientNet과 비교를 하였고 결과는 위의 표와 같습니다. ViT-L/16이 모든 task에서 BiT-L보다 나은 결과를 보였고, computational resource도 적게 들었습니다. ViT-H/14는 어려운(challenging) 데이터셋(ImageNet, CIFAR-100, VTAB)에서도 더 좋은 결과를 보였습니다. 또한 이 모델은 이전의 SOTA모델보다 더 낮은 computing resource가 필요했는데요, 이것은 ViT의 구조적인 특징때문만이 아니라 training schedule, optimizer, weight decay등과 같은 다른 parameter덕분이라고 말합니다.
4.3 Pre-training data requirements
4.4 Scaling Study
4.5 Inspecting Vision Transformer
5. Conclusion
논문에서는 이미지를 sequence of patch로 보고 이것은 standard Transformer encoder에 입력했습니다. 그리고 이런 모델은 거대한 데이터셋에 학습되었을 때 좋은 성능을 보였습니다. ViT는 많은 이미지 분류 데이터셋에서 SOTA 모델과 비슷하거나 좋은 성능을 보였고, 또한 pre-train하는데 부담이 적었습니다.
하지만 ViT는 컴퓨터비전에서의 다른 task들(detection, segmentation)에서도 적용해야하는다는 challenge가 남아있습니다. 또한 논문에서는 self-supervised pre-training 방법을 찾아야한다고 말합니다.